您的位置:
您的位置: 【】
【】
挂机也能赚钱?教你用显卡挖矿赚美元

|
HD5870/6870系列的VLIW5流处理器架构 想必大家都知道A卡有着海量的流处理器,基本上同级别A卡的流处理器数量是N卡的三倍以上。AMD采用的是VLIW(超长指令)5D/4D SIMD(单指令多数据流)架构,这样的架构可以用较少的晶体管开销制造出庞大规模的运算单元。 而NVIDIA从DX10时代开始就放弃了传统的Shader架构设计,开发了全新的MIMD(多指令多数据流)架构,将所有的运算单元全部打散,这样每个流处理器都能上到更高的频率,实现更高的效率。但代价就是晶体管消耗比较大,NVIDIA将大量晶体管耗费在了指令发射器和分配单元上面,导致同等规模的GPU,NVIDIA架构的流处理器数量要远少于AMD架构。 简言之,AMD就是暴力堆流处理器而不考虑运算效率,而NVIDIA是大幅改善了运算效率但流处理器数量较少。最终的结果就是双方各有所长,在各种3D游戏当中几乎就是平手,而在通用计算应用当中N卡要占上风,但N卡的领先优势可能还不是效率问题,而是软件优化和程序开发比较到位。 但有一种情况N卡就非常吃亏了,如果某个应用程序当中没有特别复杂的指令,而只是类似穷举算法或者一堆海量数据需要处理的话,这种无脑的操作最适合AMD的架构去处理,因为它在理论浮点运算能力方面有着绝对优势,而不用考虑运算效率问题,海量的数据自会喂饱每一个流处理器,它们不会有任何空闲的时间,自然性能无限接近理论值。
因为比特币的流行,高端A卡的销量特别好 如果您还没尝试过显卡挖矿的话,不妨按照本文的教程去试试看。如果您本来就是一个24小时不关机的下载狂人,在疯狂下载的同时开着挖矿程序的话,那么电费和网费绝对可以帮你赚回来。如果您现在打算专门组一套超级电脑去挖掘比特币的话,那就有点得不偿失了,因为现在的产量大不如前。 比特币挖矿是继蛋白质折叠(Foding@Home)、外星人分析(Set@Home)之后的又一大显卡分布式运算程序,其共性就是GPU的运算能力比CPU强很多!挖矿器直接与金钱挂钩的性质让它从一开始就吸引了不少人专门去做挖矿运算。 但实际上,比特币挖矿这种无聊的算法并没有多少实际意义,世界各地用户的运算能力被白白的浪费掉了,与其让用户做一些无聊的算法,不如把运算能力收集起来卖给特殊的企业客户,这样用户在赚钱的同时,也在源源不断的为各行各业输出运算能力,这才是分布式计算的真谛!
|


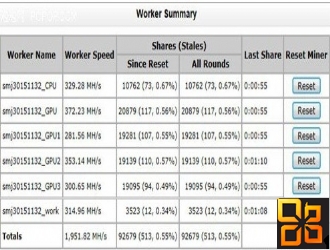
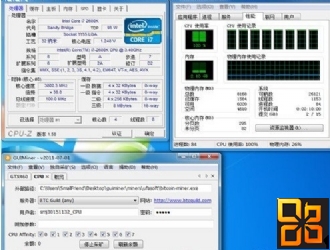
 牛人之作。
牛人之作。
 [上两篇]
[上两篇]
 网友评论
网友评论-
没有资料



 @好耶网络
Processed In:-2.0703-Seconds, CMS-28Queries-Amazon Web Services
@好耶网络
Processed In:-2.0703-Seconds, CMS-28Queries-Amazon Web Services